
深度学习在AI教育中的应用及其关键技术探究非洲女孩巴特曼因有巨臀,一生被赤身裸体展览,死后还被做成标本
深度学习技术可以在AI教育中被广泛应用,这篇文章里,作者就进行了介绍,帮助大家更深刻地理解深度学习技术的基本原理及应用,了解深度学习技术在AI教育中的广泛前景,一起来看看吧。

摘要:本文介绍了深度学习技术的基本原理,包括神经网络结构和工作原理、激活函数的选择和作用、损失函数的定义和优化方法以及反向传播算法的实现细节。然后,以智能教育辅助系统为例,说明了深度学习技术在AI教育中的应用。接着,介绍了数据预处理和特征工程的重要性,包括数据清洗和去噪处理、数据标准化和归一化以及特征选择和降维技术。最后,介绍了模型构建和训练的关键步骤,包括深度学习模型的选择和设计、模型初始化和参数调整、批量梯度下降和优化算法以及学习率调整和模型评估。
通过这些步骤,可以提高深度学习模型在AI教育中的应用效果和性能。
关键字:深度学习;神经网络; AI教育
引言:随着人工智能技术的不断发展,深度学习作为其中的重要分支,在各个领域都有广泛的应用。在教育领域,深度学习技术可以为学生提供更个性化、精准的教育支持,提高学习效果。
本文旨在介绍深度学习技术的基本原理以及在AI教育中的应用,包括神经网络结构和工作原理、激活函数的选择和作用、损失函数的定义和优化方法以及反向传播算法的实现细节。同时,还介绍了数据预处理和特征工程的重要性,以及模型构建和训练的关键步骤。通过深入理解和应用这些技术,可以为AI教育提供更好的支持和服务。
一、深度学习技术的基本原理
1. 神经网络结构和工作原理深度学习的核心是神经网络,它由多个神经元和层组成(图一 前馈神经网络概要简述)。神经网络的输入层接收原始数据,随后通过隐藏层逐层传递并经过激活函数的处理,最终得到输出层的结果。每个神经元接收到来自上一层的输入,并通过权重和偏置进行加权和偏移,然后将结果传递给激活函数进行非线性转换。
这种层层传递的过程称为前向传播,通过反复调整权重和偏置,神经网络能够学习到数据的复杂特征和模式。
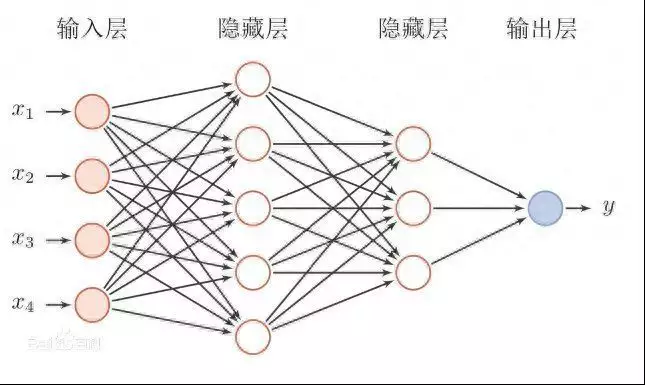
图一 前馈神经网络概要简述
2. 激活函数的选择和作用激活函数(图二 激活函数)在神经网络中具有非线性映射的功能,使得神经网络能够学习到更加复杂的函数关系。常见的激活函数包括sigmoid、ReLU和tanh等。sigmoid函数将输入值映射到0到1之间的范围【1】,适用于处理二分类问题;ReLU函数在输入大于0时输出与输入相等,小于0时输出为0,能够有效解决梯度消失的问题;【2】tanh函数将输入值映射到-1到1之间的范围,适用于对称数据集。选择适合的激活函数可以提高神经网络的表达能力和学习能力。
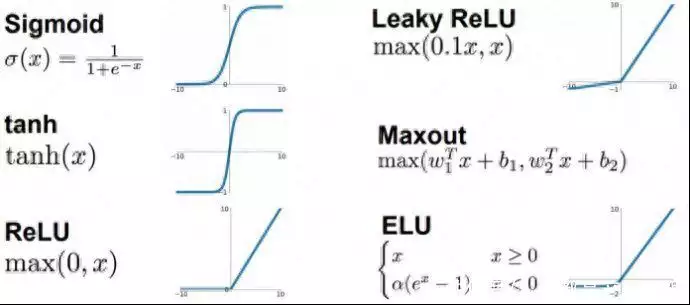
图二 激活函数
3. 损失函数的定义和优化方法损失函数(图三 常见损失函数)用于衡量神经网络预测结果与真实标签之间的差异。常见的损失函数包括均方误差(MSE)、交叉熵(Cross Entropy)等。【3】均方误差适用于回归问题,通过计算预测值与真实值的差的平方来衡量损失;交叉熵适用于分类问题,通过计算预测值与真实标签之间的差异来衡量损失。优化方法是用于最小化损失函数的算法,常见的优化方法包括梯度下降(Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和Adam优化算法等。【4】这些优化方法通过计算损失函数关于模型参数的梯度,并更新参数来使损失函数最小化。
图三 常见损失函数
4. 反向传播算法的实现细节反向传播算法(图四 反向传播算法)是深度学习中用于计算梯度的关键算法。它通过链式法则将输出层的误差逐层向后传播,计算每一层的梯度,从而实现参数的更新。具体而言,反向传播算法首先计算输出层的误差,然后逐层向前传播计算每一层的误差。在计算每一层的梯度时,需要考虑激活函数的导数和权重的导数。通过更新参数,反向传播算法能够使损失函数逐渐减小,从而提高模型的性能。
为了更好地说明深度学习技术的基本原理在AI教育中的应用,我们以智能教育辅助系统为例。假设我们想要建立一个神经网络模型,用于预测学生在数学学习中的理解程度。
首先,我们设计一个具有多个隐藏层的神经网络结构,每个隐藏层包含多个神经元。每个神经元接收来自上一层的输入,并通过权重和偏置进行加权和偏移。
然后,我们选择ReLU作为激活函数,以引入非线性映射,使神经网络能够学习到更复杂的数学概念。接下来,我们定义均方误差作为损失函数,通过计算预测结果与真实理解程度之间的差异来衡量损失。
最后,我们使用反向传播算法来计算梯度,并使用优化方法如随机梯度下降来更新参数,以使损失函数逐渐减小。
通过不断迭代训练,我们可以使神经网络模型逐渐提高对学生理解程度的预测准确性,从而为智能教育辅助系统提供个性化的学习建议和辅导。通过深度学习技术的应用,我们可以为学生提供更精准、有效的教育支持,提升他们在数学学习中的学习效果。
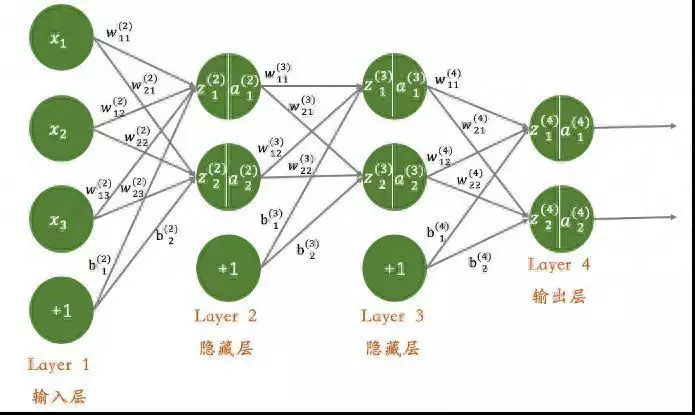
图四 反向传播算法
二、数据预处理和特征工程
1. 数据清洗和去噪处理在AI教育中,数据预处理是非常重要的步骤,它包括数据清洗和去噪处理。
数据清洗是指对原始数据进行筛选、过滤和去除错误或无效数据的过程。例如,在学生学习行为数据中,可能存在缺失值、异常值或错误数据,需要进行处理。
去噪处理是指对数据中的噪声进行处理,以减少对模型的干扰。常见的去噪处理方法包括平滑处理、滤波处理和离群点检测等。通过数据清洗和去噪处理,可以提高数据的质量和可靠性,为后续的特征工程和模型训练提供可靠的数据基础。
2. 数据标准化和归一化数据标准化和归一化是对数据进行预处理的常用方法,用于将不同尺度和范围的数据统一到相同的标准上。数据标准化是指将数据转化为均值为0、标准差为1的标准正态分布;数据归一化是指将数据缩放到特定的范围,如[0, 1]或[-1, 1]。标准化和归一化可以消除数据之间的量纲差异,避免某些特征对模型的影响过大。
常见的标准化和归一化方法包括Z-score标准化和最大最小值归一化。通过数据标准化和归一化,可以提高特征的可比性和模型的稳定性。(图五 Z-score和T-score的区别)
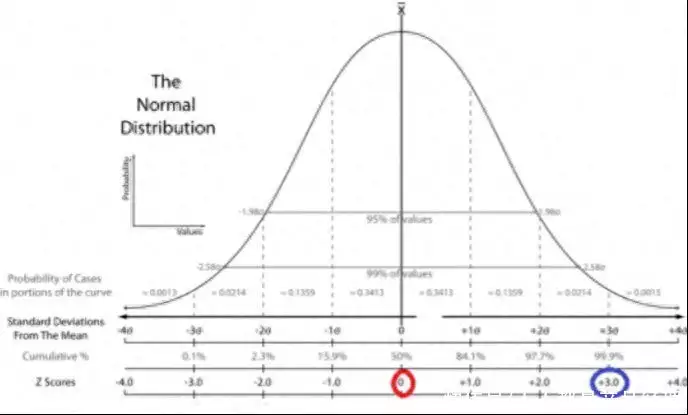
图五 Z-score和T-score的区别
3. 特征选择和降维技术在特征工程中,特征选择和降维技术是用于提取和选择最相关特征的重要方法。
特征选择是指从原始特征中选择最相关的特征子集,以减少特征维度和提高模型性能。常见的特征选择方法包括相关性分析、信息增益、卡方检验和L1正则化等。
降维技术是指将高维特征空间映射到低维空间,以减少特征维度和提高计算效率。常见的降维技术包括主成分分析(PCA)和线性判别分析(LDA)。通过特征选择和降维技术,可以提高模型的泛化能力、减少计算复杂度,并提高模型的可解释性。
为了更好地说明数据预处理和特征工程在AI教育中的应用,我们以学生学习行为数据为例。假设我们收集了学生的学习时间、学习资源使用情况和问题解答情况等多个特征。
首先,我们进行数据清洗,去除缺失值和异常值,以确保数据的质量。接下来,我们对数据进行标准化,将不同尺度的特征转化为均值为0、标准差为1的标准正态分布,以消除特征之间的量纲差异。然后,我们进行特征选择,使用相关性分析和信息增益等方法选择与学习成绩相关性较高的特征子集。最后,我们可以使用PCA进行降维,将高维的学习行为特征映射到低维空间,以减少特征维度并提高模型的计算效率。
通过数据预处理和特征工程,我们可以提取出最相关的学习行为特征,并将其转化为适合模型训练的形式,从而为个性化教育提供更准确和有效的支持。
三、模型构建和训练
1. 深度学习模型的选择和设计在AI教育中,选择和设计合适的深度学习模型是非常重要的。根据任务的不同,可以选择不同类型的深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)和变换器(Transformer)等。
模型的设计需要考虑输入数据的特点和任务的复杂性。例如,在图像分类任务中,可以选择使用卷积神经网络来提取图像特征;在序列预测任务中,可以选择使用循环神经网络来建模序列数据。同时,还需要考虑模型的深度、宽度和激活函数等方面的设计,以提高模型的表达能力和学习能力。
2. 模型初始化和参数调整在深度学习模型的训练中,模型的初始化和参数调整是非常关键的步骤。
模型的初始化是指对模型的参数进行合理的初始赋值。常见的初始化方法包括随机初始化和预训练初始化。随机初始化将模型的参数初始化为随机值,预训练初始化使用预训练好的模型参数作为初始值。
参数调整是指通过训练数据不断调整模型的参数,使得模型能够更好地拟合数据。参数调整可以使用梯度下降算法和反向传播算法来更新模型的参数,使模型逐渐优化。此外,还可以使用正则化技术如L1正则化和L2正则化来控制模型的复杂度,避免过拟合问题。
3. 批量梯度下降和优化算法在深度学习模型的训练中,批量梯度下降和优化算法是常用的方法。
批量梯度下降是指将训练数据划分为小批量进行训练,通过计算每个批量的梯度来更新模型的参数。这种方法可以加快模型的训练速度和降低计算成本。
优化算法是指在梯度下降的基础上对模型参数进行优化的算法。常见的优化算法包括随机梯度下降(SGD){图六 随机梯度下降}、动量法(Momentum)、自适应矩估计(Adam)等。这些优化算法通过调整学习率和动量等参数来提高模型的训练效果和收敛速度。
图六 随机梯度下降
4. 学习率调整和模型评估在深度学习模型的训练过程中,学习率调整和模型评估是必不可少的步骤。
学习率是指模型在每次参数更新时的步长大小。学习率的选择对模型的训练效果和收敛速度有着重要影响。常见的学习率调整方法包括固定学习率、学习率衰减和自适应学习率等。
模型评估是指对训练过程中的模型进行评估和验证。可以使用交叉验证等方法来评估模型的泛化能力。同时,还可以使用各种指标如准确率、召回率、F1值等来评估模型的性能。通过调整学习率和模型参数,不断进行模型评估和调优,可以提高模型的性能和泛化能力。
为了更好地说明模型构建和训练在AI教育中的应用,我们以智能作业批改系统为例。假设我们想要建立一个神经网络模型,用于自动批改学生的数学作业。
首先,我们选择合适的深度学习模型,如卷积神经网络(CNN),用于提取作业中的数学表达式特征。然后,我们进行模型初始化,将模型的参数进行随机初始化。接下来,我们使用批量梯度下降算法来更新模型的参数,通过计算每个批量的梯度来优化模型。同时,我们使用学习率调整方法,如学习率衰减,来逐渐降低学习率,以提高模型的收敛速度。在模型训练过程中,我们进行模型评估,使用交叉验证等方法评估模型的泛化能力,并使用准确率和召回率等指标评估模型的性能。
通过不断调整模型的参数和优化算法,我们可以提高智能作业批改系统的准确性和效率,为学生提供更好的作业批改服务。
四、总结与展望
本文介绍了深度学习技术在AI教育中的应用及其关键技术。首先,我们讨论了深度学习的基本原理,包括神经网络结构和工作原理、激活函数的选择和作用、损失函数的定义和优化方法以及反向传播算法的实现细节。然后,我们探讨了数据预处理和特征工程的重要性,包括数据清洗和去噪处理、数据标准化和归一化以及特征选择和降维技术。最后,我们介绍了模型构建和训练的关键步骤,包括深度学习模型的选择和设计、模型初始化和参数调整、批量梯度下降和优化算法以及学习率调整和模型评估。
随着深度学习技术的不断发展和AI教育的广泛应用,我们可以看到深度学习在教育领域的潜力和前景。未来,深度学习技术将进一步提高智能教育系统的个性化和自适应能力,为学生提供更精准、有效的学习支持。同时,随着数据的不断积累和算法的不断优化,深度学习模型的性能和泛化能力也将得到进一步提升。此外,随着深度学习技术的不断演进,我们还可以期待更多新的技术和方法的出现,如迁移学习、生成对抗网络等,进一步推动AI教育的发展。
然而,深度学习在AI教育中仍面临一些挑战。首先,数据隐私和安全问题需要得到有效的解决,以保障学生数据的隐私和安全。其次,深度学习模型的解释性和可解释性仍然是一个难题,我们需要进一步研究和开发可解释的深度学习模型,以增加对模型决策的理解和信任。此外,教育领域的数据获取和标注也是一个挑战,我们需要更多的合作和资源共享来解决这个问题。
总的来说,深度学习技术在AI教育中具有广阔的应用前景,并且在不断地发展和完善中。通过不断地研究和创新,我们可以进一步推动深度学习在教育领域的应用,为学生提供更好的学习体验和教育支持。
参考文献:
[1]徐嘉昕,钱凯,蒋立虹.机器学习算法在肺癌临床诊断及生存预后分析中的应用[J].中国胸心血管外科临床杂志,2022,29(06):777-781.
[2]杨继兰. 基于特征深度分析的行人再识别技术研究[D].沈阳理工大学,2020.DOI:10.27323/d.cnki.gsgyc.2020.000263.
[3]黄成强.结合深度卷积神经网络的智能白平衡研究[J].光电子·激光,2020,31(12):1278-1287.DOI:10.16136/j.joel.2020.12.0245.
[4]李巧玲,关晴骁,赵险峰.基于卷积神经网络的图像生成方式分类方法[J].网络与信息安全学报,2016,2(09):40-48.
本文由 @老秦Talk 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。


相关文章
- 2月23日克来机电涨停分析:自动刹车,人形机器人,机器人概念热股
- 机器人公司Figure融资6.75亿美元:贝索斯微软英伟达OpenAI联合投资
- 优必选人形机器人“入职”车企
- 格力电器公布国际专利申请:“机器人脱困方法及装置、处理器和机器人”
- 光大证券:英伟达将发布的机器人领域成果 有望带来人形机器人板块催化终于有老板接得住00后的离职信了,霸气回应尽显格局,网友:牛!
- 黄强主持召开研究人工智能和机器人产业发展专题会议 加快抢占人工智能和机器人产业发展新赛道她是孙红雷亲妹妹,孙俪都恭敬她3分,演技高却永远捧不红!
- 国泰君安:国内外人形机器人厂商纷纷推出各自产品 推动产业化进程周润发赵雅芝时隔40年再同框!许文强已白发苍苍,冯程程依旧甜
- 贝佐斯和英伟达将加入OpenAI投资人形机器人初创公司Figure明星最想删除的艺考照片:娜扎发际线高,杨幂土气,看到周冬雨笑了
- 硅谷大佬们都向这家初创投了钱!类人型机器人是下一个风口?她因长得太漂亮2岁出道,演“小芈月”红遍全国,如今长成厌世脸
- 人形机器人,上班了!
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~